서론
데이터 분석 과정에서 가장 중요한 단계 중 하나는 자료를 요약하고, 통계적으로 의미 있는 형태로 정리하는 것이다. 원시 데이터(raw data)는 보통 복잡하고 정리가 필요한 경우가 많으며, 이를 효율적으로 정리하지 않으면 분석의 방향을 설정하는 것이 어려워질 수 있다. 이러한 과정에서 R의 대표적인 데이터 처리 패키지인 dplyr과 tidyr이 강력한 도구로 활용된다.
dplyr은 데이터 프레임을 다룰 때 가장 널리 사용되는 패키지로, 직관적인 문법과 강력한 기능을 제공한다. 특히, 데이터를 요약하고 통계 테이블을 생성하는 과정에서 코드의 가독성(tidy evaluation)을 높이고 실행 속도를 최적화할 수 있다는 점에서 유용하다. 특히, 연속적인 데이터 변환에서 %>%(pipe 연산자)를 활용하면 여러 연산을 논리적으로 연결하여 가독성을 높일 수 있다.
통계 테이블을 만들 때 데이터는 종종 정리되지 않은 형태(untidy data)로 존재하며, 분석을 위해 올바른 형태로 변환해야 하는 경우가 많다. tidyr 패키지는 이러한 데이터 정리 과정에서 필수적인 역할을 한다. tidyr을 사용하면 넓은 형식(Wide format)과 긴 형식(Long format)의 자료로 상호 변환이 가능하다. 또한 결측값 및 불완전한 데이터 정리하는데 유용하게 사용된다.
대부분의 데이터 정리는 요약(summarization) 과 변환(transformation) 이 함께 이루어진다. dplyr과 tidyr은 각각의 역할을 수행하며, 함께 사용하면 더욱 강력한 데이터 처리 능력을 발휘할 수 있다.
이처럼 dplyr은 데이터를 요약하고 통계를 생성하는 역할을 하며, tidyr은 정리되지 않은 데이터를 보다 분석하기 쉬운 형태로 변환하는 역할을 한다. 따라서, 통계 테이블을 만들거나 데이터를 정리하는 모든 과정에서 dplyr과 tidyr은 필수적인 도구**이며, 이를 활용하면 데이터 분석의 효율성과 신뢰성을 크게 향상시킬 수 있다.
데이터의 요약
이 절에서는 요약통계량을 도출하거나 보고서로 올리기위해 자료를 요약하여 정리하는 방법을 보이고자 한다.
먼저, 함수들을 설명하기 위한 간단한 데이터프레임을 만들어본다.
코드
<- data.frame (= c ("홍길동" , "김영희" , "박찬호" , "이소라" , "최민식" ),= c ("서울" , "부산" , "서울" , "인천" , "부산" ),= c (25 , 30 , 35 , 40 , 28 ),= c (80 , 90 , 75 , 82 , 95 ):: kable (df)
그릅의 지정: group_by()
특정 열(또는 여러 열)을 기준으로 행들을 묶어 그룹한다.
그룹화 후에는 요약summarize(), 변환mutate(), 혹은 재구조화reframe() 등의 작업을 그룹 단위로 수행할 수 있다.
코드
<- df %>% group_by (도시)
# A tibble: 5 × 4
# Groups: 도시 [3]
이름 도시 나이 점수
<chr> <chr> <dbl> <dbl>
1 홍길동 서울 25 80
2 김영희 부산 30 90
3 박찬호 서울 35 75
4 이소라 인천 40 82
5 최민식 부산 28 95
결과물을 보면 눈에 보이는 데이터는 바뀌지 않지만, 내부적으로 도시를 기준으로 데이터가 ’그룹화’된 상태가 된다. 이후에 summarize(), reframe() 등을 하면 “도시별”로 계산한다.
자료의 요약: summarize() 또는 summarise()
코드
%>% group_by (도시) %>% summarize (` 평균나이 ` = mean (` 나이 ` ),` 평균점수 ` = mean (` 점수 ` ),` 인원수 ` = n ()
# A tibble: 3 × 4
도시 평균나이 평균점수 인원수
<chr> <dbl> <dbl> <int>
1 부산 29 92.5 2
2 서울 30 77.5 2
3 인천 40 82 1
제이터프레임의 컬럼명
dplyr과 tidyr 제공되는 함수들은 간결한 연산(tidy evaluation )의 방식이 적용되어 데이터프레임의 컬럼 이름을 나타낼 때 영문과 한글 상관없이 따옴표를 붙이지 않고 없이 사용할 수 있다. 하지만 컬럼명을 한글로 사용하는 경우 간결한 연산이 적용되지 않는 다른 패키지의 함수와 같이 사용하는 경우 문제가 발생할 수 있다.
따라서 한글 컬럼 이름은 언제나 역따옴표 `` 로 묶어주는 것이 안전하다.
컬럼의 위치 이동: relocate()
코드
<- df %>% relocate (도시, .before = 이름)
도시 이름 나이 점수
1 서울 홍길동 25 80
2 부산 김영희 30 90
3 서울 박찬호 35 75
4 인천 이소라 40 82
5 부산 최민식 28 95
컬럼의 선택: select()
원하는 열만 선택하거나, 열의 순서를 지정하는 데 사용한다.
데이터에서 특정 열만 추출하거나, 불필요한 열을 제거하고 싶을 때 사용한다.
다음 예시는 이름과 점수 열만 선택
코드
<- df %>% select (이름, 점수)
이름 점수
1 홍길동 80
2 김영희 90
3 박찬호 75
4 이소라 82
5 최민식 95
재구조화: reframe()
summarize()와 비슷하게 그룹화된 데이터를 재구조화하되, 결과를 그룹별 여러 행으로 반환할 수도 있다.
dplyr 1.1.0부터 추가된 기능으로, 기존 summarize()가 그룹당 “요약된 한 행”을 반환했던 것과 달리, reframe()은 그룹별로 여러 행을 만들어낼 수 있다.
다음 예시는 도시별로 데이터를 모은 뒤, 그 안에서 ’이름’과 ’점수’만 추려서 재구조화
코드
<- df %>% group_by (도시) %>% reframe (= mean (점수)
# A tibble: 5 × 4
도시 이름 점수 평균도시점수
<chr> <chr> <dbl> <dbl>
1 부산 김영희 90 92.5
2 부산 최민식 95 92.5
3 서울 홍길동 80 77.5
4 서울 박찬호 75 77.5
5 인천 이소라 82 82
도시별로 그룹화한 뒤 각 그룹 내부에서 모든 이름과 점수를 그대로 나열하면서, 같은 그룹 내 평균 점수(평균도시점수)를 함께 표시한다.
결과는 그룹당 여러 행(그룹에 속한 사람 수만큼)이 나올 수 있으며, 요약 통계는 반복되어 표시한다.
컬럼명 변경 rename() 또는 rename_with
특정 규칙에 따라 여러 열의 이름을 한꺼번에 변경할 때 사용한다.
예를 들어, 모든 열 이름에 접두사(prefix)를 붙이거나, 대소문자 변환 등을 할 수 있다.
코드
<- df %>% rename (city = 도시, name = 이름)
name city 나이 점수
1 홍길동 서울 25 80
2 김영희 부산 30 90
3 박찬호 서울 35 75
4 이소라 인천 40 82
5 최민식 부산 28 95
코드
<- df %>% rename_with (.fn = ~ paste0 ("new_" , .), .cols = everything ())
new_이름 new_도시 new_나이 new_점수
1 홍길동 서울 25 80
2 김영희 부산 30 90
3 박찬호 서울 35 75
4 이소라 인천 40 82
5 최민식 부산 28 95
정열: arrange()
코드
<- df %>% arrange (점수)
이름 도시 나이 점수
1 박찬호 서울 35 75
2 홍길동 서울 25 80
3 이소라 인천 40 82
4 김영희 부산 30 90
5 최민식 부산 28 95
컬럼 묶기 across()
여러 열에 대해 동일한 함수를 일괄 적용할 때 사용한다.
mutate(), summarize() 등에서, 선택한 여러 열에 대해 한꺼번에 연산을 적용할 수 있다.
다음 예시는 나이와 점수를 각각 2배로 만들고, 새로운 열(나이2배, 점수2배)을 생성
코드
<- df %>% mutate (across (.cols = c (나이, 점수), # 어떤 열에 적용할지 .fns = ~ . * 2 , # 어떤 함수를 적용할지 .names = "{.col}2배" # 새로운 열 이름 형식
이름 도시 나이 점수 나이2배 점수2배
1 홍길동 서울 25 80 50 160
2 김영희 부산 30 90 60 180
3 박찬호 서울 35 75 70 150
4 이소라 인천 40 82 80 164
5 최민식 부산 28 95 56 190
데이터의 변환
데이터프레임의 형태를 바꾸는 중요한 함수 2개를 소개한다.
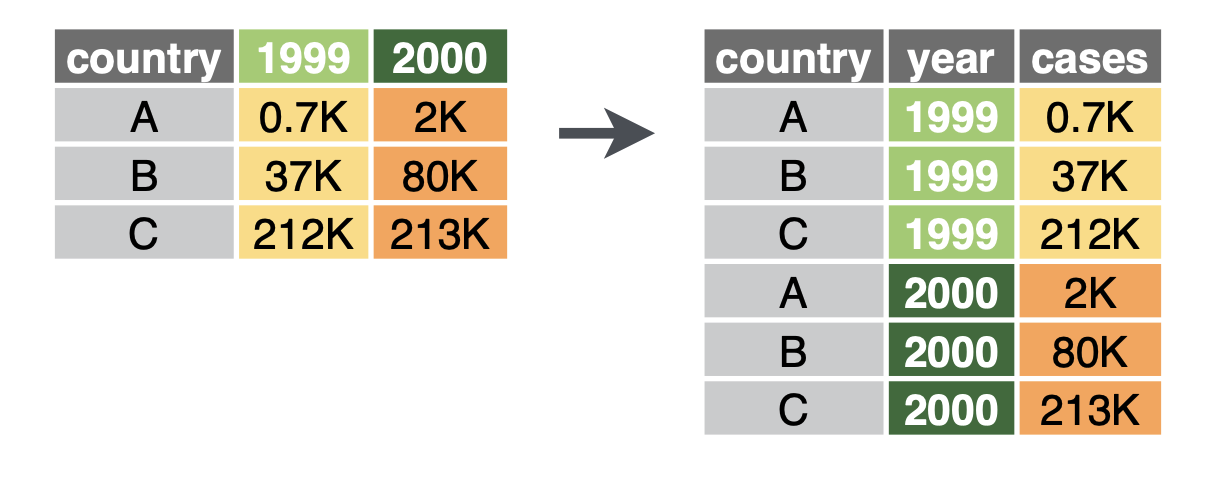
긴 형식: pivot_longer()
가로 방향으로 나열된 데이터를 세로 방향(긴 형태, Long format)로 변환한다.
긴 형식으로 변환(그림출처: tidyr 홈페이지)
보통 측정 항목(예: 나이, 점수)이 열로 되어 있을 때, 이를 “변수 이름”과 “값”의 두 열로 합쳐서 “길게”(long) 만들 때 쓰인다.
다음 예시는 나이와 점수 열을 세로 방향으로 길게 변환
코드
<- df %>% pivot_longer (cols = c (나이, 점수),names_to = "측정항목" ,values_to = "값"
# A tibble: 10 × 4
이름 도시 측정항목 값
<chr> <chr> <chr> <dbl>
1 홍길동 서울 나이 25
2 홍길동 서울 점수 80
3 김영희 부산 나이 30
4 김영희 부산 점수 90
5 박찬호 서울 나이 35
6 박찬호 서울 점수 75
7 이소라 인천 나이 40
8 이소라 인천 점수 82
9 최민식 부산 나이 28
10 최민식 부산 점수 95
cols: 세로로 변환할(길게 만들) 대상 열을 지정
names_to: 기존 열 이름이 어떤 새 열 이름으로 저장될지 지정
values_to: 기존 열 값이 어떤 새 열 이름으로 저장될지 지정
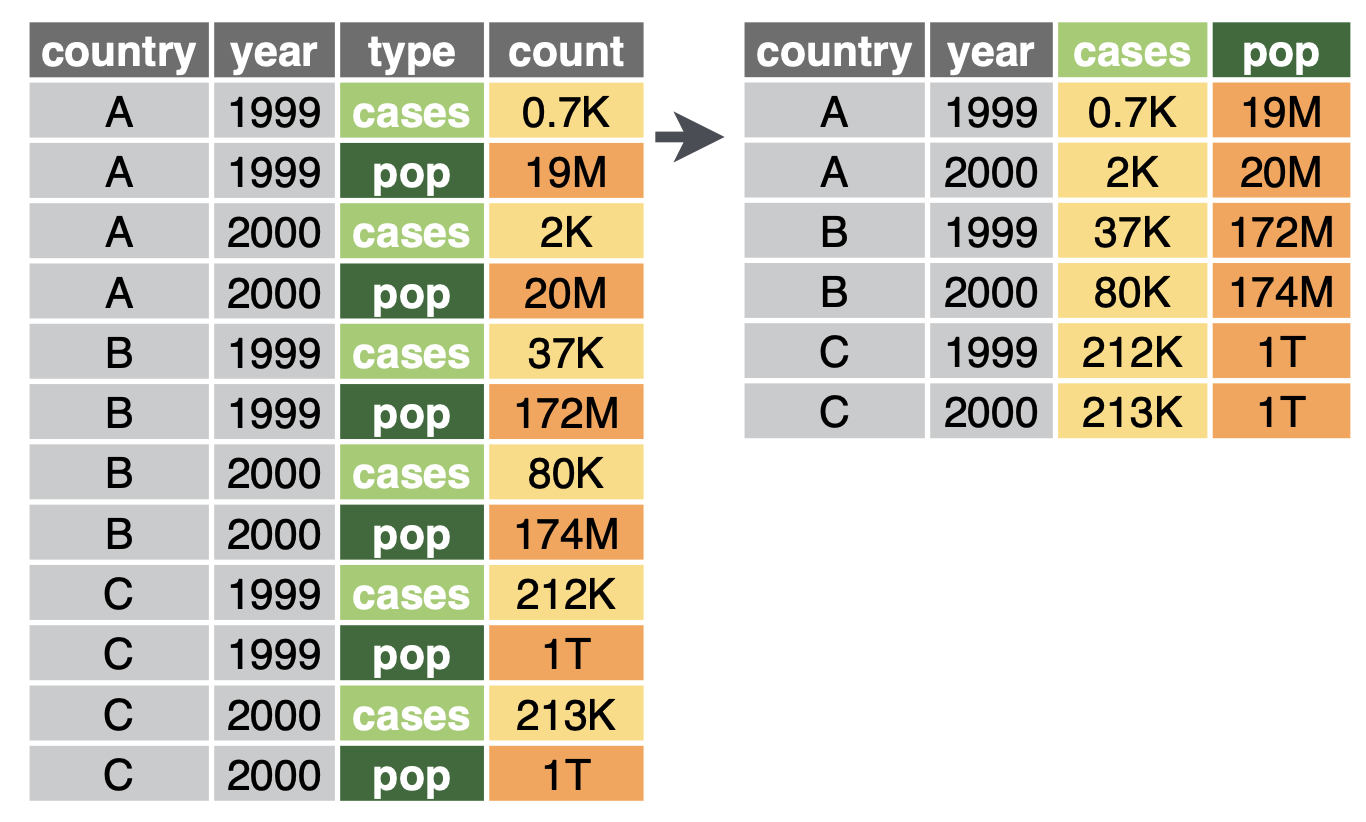
넓은 형식: pivot_wider()
세로 방향(긴 형태)로 나열된 데이터를 가로 방향(넓은 형태)으로 변환한다.
넓은 형식으로 변환(그림출처: tidyr 홈페이지)
코드
<- df_long %>% pivot_wider (names_from = "측정항목" ,values_from = "값"
# A tibble: 5 × 4
이름 도시 나이 점수
<chr> <chr> <dbl> <dbl>
1 홍길동 서울 25 80
2 김영희 부산 30 90
3 박찬호 서울 35 75
4 이소라 인천 40 82
5 최민식 부산 28 95
names_from: 어떤 열의 값을 “열 이름”으로 펼칠지 지정
values_from: 어떤 열의 값을 “열 값”으로 사용할지 지정
다시 이름, 도시를 그대로 두면서, 나이와 점수가 각각 열로 복원된 형태가 된다.
실습: 데이터요약표 만들기
이제 실제 데이터를 이용하여 분할표와 요약통계표를 구해보자.
코드
load (here:: here ("data" , "physical100_data.RData" ))ls ()
[1] "df" "df_across" "df_arranged" "df_grouped" "df_long"
[6] "df_reframed" "df_relocated" "df_renamed1" "df_renamed2" "df_selected"
[11] "df_wide" "df1_youth"
소개
코드
ID CENTER_NM TEST_AGE TEST_YMD TEST_YEAR TEST_SEX ITEM_F001 ITEM_F002
<int> <char> <int> <Date> <int> <char> <num> <num>
1: 1 삼척 13 2018-10-12 2018 남성 172.5 62.7
2: 2 동작 18 2018-05-17 2018 남성 180.8 79.2
3: 3 마포 16 2018-05-02 2018 남성 169.0 63.0
4: 4 강릉 17 2019-04-01 2019 여성 151.9 52.5
5: 5 남원 14 2020-09-22 2020 여성 150.1 61.2
6: 6 안동 17 2018-10-22 2018 남성 173.6 53.5
7: 7 원주 15 2023-05-08 2023 여성 163.8 66.2
8: 8 태백 14 2022-05-17 2022 남성 162.9 53.4
9: 9 성남 16 2018-09-19 2018 남성 163.1 63.9
10: 10 서초 13 2019-05-21 2019 남성 169.3 66.7
ITEM_F009 ITEM_F012 ITEM_F018 ITEM_F020 ITEM_F022 ITEM_F028
<num> <num> <num> <num> <num> <num>
1: NA -8.2 21.1 25 NA 42.2
2: NA 8.5 24.2 64 245 78.1
3: 27 -7.0 22.1 36 165 52.5
4: NA 10.9 22.8 17 NA 36.7
5: NA 27.5 27.2 18 137 37.2
6: 27 9.0 17.8 29 220 71.7
7: NA 25.2 24.7 15 133 45.2
8: NA 9.6 20.1 31 210 45.7
9: NA 17.6 24.0 50 NA 58.3
10: NA 1.2 23.3 20 150 42.1
요약통계표
df1_youth에서 성별과 각 년도별로 그룹화 해서 도수,평균 등을 계산.
코드에 대해 설명하면,
원천자료 df1_youth 를 지정하고
TEST_SEX, TEST_YEAR, ITEM_F001 컬럼을 선택하고TEST_SEX, TEST_YEAR 컬럼으로 그룹화한 후신장(ITEM_F001) 에 대한 그룹별 돗수, 평균, 표준편차를 계산
코드
<- df1_youth %>% select (TEST_SEX, TEST_YEAR, ITEM_F001) %>% group_by (TEST_SEX, TEST_YEAR) %>% summarize (n = n (), MEAN = mean (ITEM_F001, na.rm= TRUE ),SD = sd (ITEM_F001, na.rm= TRUE ),.groups = "drop" # 그룹을 모두 해제
# A tibble: 14 × 5
TEST_SEX TEST_YEAR n MEAN SD
<chr> <int> <int> <dbl> <dbl>
1 남성 2017 85 188. 173.
2 남성 2018 131 171. 6.38
3 남성 2019 140 171. 7.49
4 남성 2020 20 172. 5.26
5 남성 2021 29 173. 6.61
6 남성 2022 66 174. 6.28
7 남성 2023 89 171. 7.79
8 여성 2017 83 160. 6.27
9 여성 2018 90 160. 5.38
10 여성 2019 96 160. 5.33
11 여성 2020 13 160. 4.28
12 여성 2021 22 159. 4.11
13 여성 2022 52 161. 5.59
14 여성 2023 84 161. 6.05
분할표
남여별로 각 년도에 돗수를 분할표로 구해본다.
원천자료 df1_youth 를 지정하고
TEST_SEX, TEST_YEAR 컬럼을 선택하고TEST_SEX, TEST_YEAR 컬럼으로 그룹화한 후각 그룹의 조합의 돗수를 n 으로 계산한다.
측정연도 TEST_YEAR 의 숫자 앞에 Y 를 붙여서 새로운 열이름을 만들고, 성별과 연도에 해당하는 돗수로 교차표를 만든다.
코드
<- df1_youth %>% select (TEST_SEX, TEST_YEAR) %>% group_by (TEST_SEX, TEST_YEAR) %>% summarize (n = n ()) %>% pivot_wider (names_from = TEST_YEAR,values_from = n, names_prefix = "Y" )
`summarise()` has grouped output by 'TEST_SEX'. You can override using the
`.groups` argument.
코드
# A tibble: 2 × 8
# Groups: TEST_SEX [2]
TEST_SEX Y2017 Y2018 Y2019 Y2020 Y2021 Y2022 Y2023
<chr> <int> <int> <int> <int> <int> <int> <int>
1 남성 85 131 140 20 29 66 89
2 여성 83 90 96 13 22 52 84
통계표 만들기
통계표를 만드는 방법을 여러가지 보일 것이다.
우선 통계량을 구하는 함수를 코드에 일일히 입력하기 번거로우니 여러 개의 지정된 함수와 이름을 list로 묶어서 my_summ_func에 저장하는 방법을 사용한다.
각 측정항목에 적용할 통계 함수와 출력값의 이름을 지정한다.
코드
<- list (= ~ sum (! is.na (.x)),= ~ sum (is.na (.x)),= ~ mean (.x, na.rm = TRUE ),= ~ sd (.x, na.rm = TRUE ),= ~ min (.x, na.rm = TRUE ),= ~ quantile (.x, probs = 0.25 , na.rm = TRUE ),= ~ median (.x, na.rm = TRUE ),= ~ quantile (.x, probs = 0.75 , na.rm = TRUE ),= ~ max (.x, na.rm = TRUE )
~sum,~mean, 등등: 함수를 쓸때 간단하게 작성하는 방법
.x: 자리표시자로써 열 또는 원소를 지칭하는 의미
na.rm: 결측치(NA)를 제거하고 계산할지 여부를 물어보는 것
1단계 통계표
간단한 통계표부터 보여본다.
원천자료 df1_youth를 지정하고
TEST_SEX, TEST_YEAR 컬럼을 선택하고my_summ_func 에서 정의한 함수를 열이름이 ITEM을 포함한 모든열에 적용한다.
코드
<- df1_youth %>% group_by (TEST_SEX, TEST_YEAR) %>% summarise (across (contains ("ITEM" ), my_summ_func,.names = "{.col}-{.fn}" ))
`summarise()` has grouped output by 'TEST_SEX'. You can override using the
`.groups` argument.
코드
# A tibble: 14 × 74
# Groups: TEST_SEX [2]
TEST_SEX TEST_YEAR `ITEM_F001-개수` `ITEM_F001-결측개수` `ITEM_F001-평균`
<chr> <int> <int> <int> <dbl>
1 남성 2017 85 0 188.
2 남성 2018 131 0 171.
3 남성 2019 140 0 171.
4 남성 2020 20 0 172.
5 남성 2021 29 0 173.
6 남성 2022 66 0 174.
7 남성 2023 89 0 171.
8 여성 2017 83 0 160.
9 여성 2018 90 0 160.
10 여성 2019 96 0 160.
11 여성 2020 13 0 160.
12 여성 2021 22 0 159.
13 여성 2022 52 0 161.
14 여성 2023 84 0 161.
# ℹ 69 more variables: `ITEM_F001-표준편차` <dbl>, `ITEM_F001-최소값` <dbl>,
# `ITEM_F001-백분위25` <dbl>, `ITEM_F001-중앙값` <dbl>,
# `ITEM_F001-백분위75` <dbl>, `ITEM_F001-최대값` <dbl>,
# `ITEM_F002-개수` <int>, `ITEM_F002-결측개수` <int>, `ITEM_F002-평균` <dbl>,
# `ITEM_F002-표준편차` <dbl>, `ITEM_F002-최소값` <dbl>,
# `ITEM_F002-백분위25` <dbl>, `ITEM_F002-중앙값` <dbl>,
# `ITEM_F002-백분위75` <dbl>, `ITEM_F002-최대값` <dbl>, …
2단계 통계표
1단계 통계표에서 pivot_longer을 사용해 추가적으로 진행을 해본다.
항목이름과 통계이름으로 구성된 얿은 열을 가진 자료를 다시 긴 행을 가진 자료로 변환
변환시 열이름을 두 열로 나누어 저장(항목이름 item과 통계량 stat)
항목이름 item열을 앞으로 배치
코드
<- aa %>% pivot_longer (! c (TEST_SEX, TEST_YEAR), names_to = c ("item" , "stat" ), names_sep= "-" , values_to = "value" )
# A tibble: 1,008 × 5
# Groups: TEST_SEX [2]
TEST_SEX TEST_YEAR item stat value
<chr> <int> <chr> <chr> <dbl>
1 남성 2017 ITEM_F001 개수 85
2 남성 2017 ITEM_F001 결측개수 0
3 남성 2017 ITEM_F001 평균 188.
4 남성 2017 ITEM_F001 표준편차 173.
5 남성 2017 ITEM_F001 최소값 145.
6 남성 2017 ITEM_F001 백분위25 165.
7 남성 2017 ITEM_F001 중앙값 170
8 남성 2017 ITEM_F001 백분위75 175.
9 남성 2017 ITEM_F001 최대값 1761
10 남성 2017 ITEM_F002 개수 85
# ℹ 998 more rows
3단계 통계표
2단계 통계표에서 pivot_wider을 진행해 추가적으로 진행을 해본다.
긴 행을 가진 자료를 측정 년도를 열로 바꾸어 긴 열을 가진 자료로 변환
항목이름과 성별순으로 자료를 정렬
코드
<- bb %>% dplyr:: relocate (item) %>% pivot_wider (names_from = TEST_YEAR, values_from = value)
# A tibble: 144 × 10
# Groups: TEST_SEX [2]
item TEST_SEX stat `2017` `2018` `2019` `2020` `2021` `2022` `2023`
<chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 ITEM_F001 남성 개수 85 131 140 20 29 66 89
2 ITEM_F001 남성 결측개수 0 0 0 0 0 0 0
3 ITEM_F001 남성 평균 188. 171. 171. 172. 173. 174. 171.
4 ITEM_F001 남성 표준편차 173. 6.38 7.49 5.26 6.61 6.28 7.79
5 ITEM_F001 남성 최소값 145. 146. 144. 161. 155 159 143.
6 ITEM_F001 남성 백분위25 165. 167. 166. 169. 170 171. 166.
7 ITEM_F001 남성 중앙값 170 172. 171. 173. 174. 174. 172.
8 ITEM_F001 남성 백분위75 175. 175. 176. 174. 177. 177. 176.
9 ITEM_F001 남성 최대값 1761 184. 189 183. 185. 189 187.
10 ITEM_F002 남성 개수 85 131 140 20 29 66 89
# ℹ 134 more rows
함수만들기
실제로 통계표를 만들고 출력하는 데까지 한번에 하는 것이 아닌 여러번의 과정을 거쳐야 한다는 것을 알고 있다.
그렇기에 여러번 돌릴 때마다 코드를 수정하면서 돌리는 것은 비효율적이므로 함수를 만들어서 필요할 때 마다 간편하게 통계표를 만드는 과정을 보려고 한다.
우선, summarise에 쓰일 통계량이 많기에 리스트 형태로 미리 지정하는 것이 편하다.
코드
<- list (` 개수 ` = ~ sum (! is.na (.x)),` 결측개수 ` = ~ sum (is.na (.x)),` 평균 ` = ~ mean (.x, na.rm = TRUE ),` 표준편차 ` = ~ sd (.x, na.rm = TRUE ),` 최소값 ` = ~ min (.x, na.rm = TRUE ),` 백분위25 ` = ~ quantile (.x, probs = 0.25 , na.rm = TRUE ),` 중앙값 ` = ~ median (.x, na.rm = TRUE ),` 백분위75 ` = ~ quantile (.x, probs = 0.75 , na.rm = TRUE ),` 최대값 ` = ~ max (.x, na.rm = TRUE )<- list (` 개수 ` = ~ n (),` 평균 ` = ~ mean (.x, na.rm = TRUE ),` 표준편차 ` = ~ sd (.x, na.rm = TRUE )
이제 직접 함수를 만들고 이해해보자.
코드
<- function (df, cols_to_row, cols_to_col, cols_to_summ, stat_fun, stat_to_column = FALSE ) {<- syms (cols_to_row)<- syms (cols_to_col)<- syms (cols_to_summ)<- df %>% group_by (!!! col1, !!! col2) %>% summarise (across (all_of (cols_to_summ), stat_fun, .names = "{.col}-{.fn}" )) %>% pivot_longer (cols = - c (!!! col1, !!! col2), names_to = c ("ITEM" , "STAT" ), names_sep= "-" , values_to = "value" ) %>% relocate (ITEM) %>% :: arrange (ITEM) %>% :: ungroup () if (stat_to_column) { <- tab1 %>% pivot_wider (names_from = all_of (c (cols_to_col,"STAT" )), values_from = value) else {<- tab1 %>% pivot_wider (names_from = all_of (cols_to_col), values_from = value) return (tab1)
우선, 입력할 인자들이 무엇인지 확인하자.
코드
function (df, # 데이터프레임 입력 # "행 그룹”으로 사용할 열 이름(들). # “열 그룹”으로 사용할 열 이름(들). # 요약 함수(stat_fun)를 적용할 대상 열 이름(들). # 요약에 사용할 함수(예: mean, sum, sd 등). stat_to_column = FALSE # 결과를 펼칠 때(pivot_wider) 통계값(STAT)을 열 이름으로 포함할지 여부
syms
문자열 벡터를 symbol 리스트로 바꿔준다.
예를 들어 cols_to_row = c("SEX","YEAR")라면 col1은 list(quote(SEX), quote(YEAR))가 된다.
이후 !!!(splicing operator)와 함께 group_by() 등에 활용하기 위함이다.
코드
<- syms (cols_to_row)<- syms (cols_to_col)<- syms (cols_to_summ)
!!!
!!! 연산자를 쓰는 이유는, 직접함수를 만들 때 필요한 것으로 입력한 인자를 잘 인식시키기 위한 과정이라 생각하면 된다.
syms()로 만들어진 다수의 symbol 리스트를 group_by()나 pivot_longer() 등의 인자에 ’개별 인자’처럼 인식해준다.
코드
<- df %>% group_by (!!! col1, !!! col2)
즉, !!!col1 은 “col1이 가진 모든 symbol을 풀어서 인자로 넣어달라”라는 뜻이다.
예를 들어 col1이 list(quote(SEX), quote(YEAR))라면, group_by(!!!col1)는 group_by(SEX, YEAR)로 동작하게 된다.
summarise(across...
코드
summarise (across (all_of (cols_to_summ), stat_fun, .names = "{.col}-{.fn}" ))
pivot_longer(cols = ...
요약 후 만들어진 여러 통계량 열(ITEM_F001-mean, ITEM_F001-sd 등)을 세로 형태(long format)로 펼친다.
names_sep = "-"를 기준으로 ITEM과 STAT 두 부분으로 분리.
예: ITEM_F001-mean → ITEM = ITEM_F001, STAT = mean.
코드
pivot_longer (cols = - c (!!! col1, !!! col2), names_to = c ("ITEM" , "STAT" ), names_sep = "-" , values_to = "value" )
cols = -c(!!!col1, !!!col2)는 그룹 열을 제외한 모든 열을 pivot_longer 대상으로 삼는 것.
dplyr::arrange(ITEM)
dplyr패키지 안에 arrange함수를 쓴다는 의미이다.
dplyr::ungroup()
그룹화를 해제한다(추가 연산에서 혼동을 막기 위해).
if (stat_to_column) { ... } else { ... }
stat_to_column이 TRUE라면, cols_to_col과 STAT 모두를 열 이름으로 펼친다.
예: [ SEX, YEAR, STAT ] 조합이 열이 됨.
코드
if (stat_to_column) { tab1 <- tab1 %>% pivot_wider (names_from = all_of (c (cols_to_col, "STAT" )), values_from = value) }
코드
else { tab1 <- tab1 %>% pivot_wider (names_from = all_of (cols_to_col), values_from = value) }
설명만 보았을 때는 어려우니 뒤에 결과물을 보고 이해해보자.
직접만든 함수 적용
첫번 째 통계표의 경우는
행( row ) 그룹핑 기준: TEST_SEX(성별), TEST_AGE(나이)
열( column ) 그룹핑 기준: TEST_YEAR(검사연도)
통계 함수를 적용할 열들: ITEM_F001, ITEM_F002
계산할 함수: my_summ_func_2
로 표를 만들어준다.
코드
<- summ_function_general (df1_youth,c ("TEST_SEX" , "TEST_AGE" ),c ("TEST_YEAR" ),c ("ITEM_F001" , "ITEM_F002" ),stat_fun = my_summ_func_2)
`summarise()` has grouped output by 'TEST_SEX', 'TEST_AGE'. You can override
using the `.groups` argument.
코드
head (tab1,20 ) %>% kbl () %>% kable_styling ()
ITEM_F001
남성
13
개수
16.000000
20.000000
26.000000
1.000000
2.000000
3.000000
11.000000
ITEM_F001
남성
13
평균
162.350000
164.715000
164.892308
182.800000
159.400000
165.266667
165.609091
ITEM_F001
남성
13
표준편차
7.448937
6.895328
8.639024
NA
6.222540
2.663331
9.177304
ITEM_F001
남성
14
개수
16.000000
17.000000
32.000000
3.000000
2.000000
7.000000
18.000000
ITEM_F001
남성
14
평균
165.456250
168.505882
167.603125
169.433333
170.600000
171.714286
168.388889
ITEM_F001
남성
14
표준편차
5.399873
5.318067
6.567539
4.309679
11.455130
11.317159
7.085602
ITEM_F001
남성
15
개수
16.000000
22.000000
24.000000
3.000000
2.000000
15.000000
17.000000
ITEM_F001
남성
15
평균
269.781250
170.977273
173.600000
170.900000
169.700000
173.380000
174.188235
ITEM_F001
남성
15
표준편차
397.692213
6.552058
5.362592
4.622770
6.646804
4.947900
7.105005
ITEM_F001
남성
16
개수
15.000000
32.000000
23.000000
4.000000
7.000000
16.000000
11.000000
ITEM_F001
남성
16
평균
173.200000
173.031250
173.539130
170.825000
175.342857
174.031250
171.581818
ITEM_F001
남성
16
표준편차
7.156915
4.476421
6.486751
6.439138
2.869296
5.888488
5.568989
ITEM_F001
남성
17
개수
11.000000
26.000000
30.000000
5.000000
10.000000
11.000000
17.000000
ITEM_F001
남성
17
평균
175.000000
173.450000
173.573333
174.260000
173.140000
174.981818
174.352941
ITEM_F001
남성
17
표준편차
4.850979
4.888374
6.267262
4.496443
6.764154
3.136820
8.408412
ITEM_F001
남성
18
개수
11.000000
14.000000
5.000000
4.000000
6.000000
14.000000
15.000000
ITEM_F001
남성
18
평균
174.527273
174.628571
171.580000
169.325000
176.533333
176.557143
171.246667
ITEM_F001
남성
18
표준편차
5.833196
5.844054
3.834319
3.718759
2.445949
5.852772
6.460857
ITEM_F001
여성
13
개수
17.000000
11.000000
16.000000
2.000000
5.000000
10.000000
13.000000
ITEM_F001
여성
13
평균
157.288235
156.290909
156.493750
158.900000
157.360000
160.370000
159.553846
이후 tab2,tab3도 동일하게 알부분만 변경해서 통계표를 만든 결과이다.
코드
<- summ_function_general (df1_youth,c ("TEST_AGE" ), c ("TEST_YEAR" , "TEST_SEX" ),c ("ITEM_F001" , "ITEM_F002" ),stat_fun = my_summ_func_2)
`summarise()` has grouped output by 'TEST_AGE', 'TEST_YEAR'. You can override
using the `.groups` argument.
코드
head (tab2,20 ) %>% kbl () %>% kable_styling ()
ITEM_F001
13
개수
16.000000
17.000000
20.000000
11.000000
26.000000
16.000000
1.000000
2.0000000
2.000000
5.0000000
3.000000
10.000000
11.000000
13.000000
ITEM_F001
13
평균
162.350000
157.288235
164.715000
156.290909
164.892308
156.493750
182.800000
158.9000000
159.400000
157.3600000
165.266667
160.370000
165.609091
159.553846
ITEM_F001
13
표준편차
7.448937
7.663214
6.895328
5.826054
8.639024
3.423150
NA
4.9497475
6.222540
1.9060430
2.663331
4.903298
9.177304
8.704751
ITEM_F001
14
개수
16.000000
13.000000
17.000000
16.000000
32.000000
15.000000
3.000000
2.0000000
2.000000
4.0000000
7.000000
8.000000
18.000000
8.000000
ITEM_F001
14
평균
165.456250
159.900000
168.505882
159.350000
167.603125
161.040000
169.433333
155.6000000
170.600000
158.3250000
171.714286
161.875000
168.388889
158.962500
ITEM_F001
14
표준편차
5.399873
7.355723
5.318067
4.665047
6.567539
4.529869
4.309679
7.7781746
11.455130
5.3080913
11.317159
4.987341
7.085602
6.857100
ITEM_F001
15
개수
16.000000
18.000000
22.000000
13.000000
24.000000
22.000000
3.000000
2.0000000
2.000000
1.0000000
15.000000
8.000000
17.000000
18.000000
ITEM_F001
15
평균
269.781250
162.316667
170.977273
162.400000
173.600000
160.622727
170.900000
159.9500000
169.700000
162.0000000
173.380000
160.700000
174.188235
160.383333
ITEM_F001
15
표준편차
397.692213
5.818353
6.552058
6.858450
5.362592
5.114678
4.622770
3.1819805
6.646804
NA
4.947900
3.706751
7.105005
3.873021
ITEM_F001
16
개수
15.000000
14.000000
32.000000
24.000000
23.000000
21.000000
4.000000
2.0000000
7.000000
3.0000000
16.000000
7.000000
11.000000
19.000000
ITEM_F001
16
평균
173.200000
159.314286
173.031250
160.920833
173.539130
159.680952
170.825000
158.6500000
175.342857
165.0666667
174.031250
159.142857
171.581818
161.436842
ITEM_F001
16
표준편차
7.156915
5.439154
4.476421
5.050095
6.486751
5.956309
6.439138
0.4949747
2.869296
0.8504901
5.888488
7.628424
5.568989
4.344883
ITEM_F001
17
개수
11.000000
15.000000
26.000000
19.000000
30.000000
17.000000
5.000000
3.0000000
10.000000
6.0000000
11.000000
8.000000
17.000000
14.000000
ITEM_F001
17
평균
175.000000
160.960000
173.450000
161.984210
173.573333
159.347059
174.260000
161.0000000
173.140000
158.7333333
174.981818
162.437500
174.352941
162.385714
ITEM_F001
17
표준편차
4.850979
4.036760
4.888374
3.481102
6.267262
6.197491
4.496443
1.5620499
6.764154
3.7494889
3.136820
4.955210
8.408412
5.063574
ITEM_F001
18
개수
11.000000
6.000000
14.000000
7.000000
5.000000
5.000000
4.000000
2.0000000
6.000000
3.0000000
14.000000
11.000000
15.000000
12.000000
ITEM_F001
18
평균
174.527273
161.150000
174.628571
160.471429
171.580000
163.080000
169.325000
164.5000000
176.533333
156.2000000
176.557143
162.872727
171.246667
160.391667
ITEM_F001
18
표준편차
5.833196
6.338060
5.844054
6.273945
3.834319
4.930213
3.718759
5.6568542
2.445949
3.5930488
5.852772
7.072777
6.460857
8.397668
ITEM_F002
13
개수
16.000000
17.000000
20.000000
11.000000
26.000000
16.000000
1.000000
2.0000000
2.000000
5.0000000
3.000000
10.000000
11.000000
13.000000
ITEM_F002
13
평균
56.943750
52.735294
64.265000
51.027273
63.730769
49.350000
97.500000
53.0000000
72.850000
50.3800000
60.933333
59.630000
64.418182
55.638461
코드
<- summ_function_general (df1_youth,c ("TEST_SEX" , "TEST_AGE" ),c ("TEST_YEAR" ),c ("ITEM_F001" , "ITEM_F002" ),stat_fun = my_summ_func_2,stat_to_column = TRUE )
`summarise()` has grouped output by 'TEST_SEX', 'TEST_AGE'. You can override
using the `.groups` argument.
코드
head (tab3,20 ) %>% kbl () %>% kable_styling ()
ITEM_F001
남성
13
16
162.35000
7.448937
20
164.71500
6.895328
26
164.89231
8.639024
1
182.80000
NA
2
159.40000
6.2225397
3
165.26667
2.663331
11
165.60909
9.177304
ITEM_F001
남성
14
16
165.45625
5.399873
17
168.50588
5.318067
32
167.60313
6.567539
3
169.43333
4.3096790
2
170.60000
11.4551299
7
171.71429
11.317159
18
168.38889
7.085602
ITEM_F001
남성
15
16
269.78125
397.692213
22
170.97727
6.552058
24
173.60000
5.362592
3
170.90000
4.6227697
2
169.70000
6.6468037
15
173.38000
4.947900
17
174.18824
7.105005
ITEM_F001
남성
16
15
173.20000
7.156915
32
173.03125
4.476421
23
173.53913
6.486751
4
170.82500
6.4391381
7
175.34286
2.8692956
16
174.03125
5.888488
11
171.58182
5.568989
ITEM_F001
남성
17
11
175.00000
4.850979
26
173.45000
4.888374
30
173.57333
6.267262
5
174.26000
4.4964430
10
173.14000
6.7641539
11
174.98182
3.136820
17
174.35294
8.408412
ITEM_F001
남성
18
11
174.52727
5.833196
14
174.62857
5.844054
5
171.58000
3.834319
4
169.32500
3.7187588
6
176.53333
2.4459490
14
176.55714
5.852772
15
171.24667
6.460857
ITEM_F001
여성
13
17
157.28824
7.663214
11
156.29091
5.826054
16
156.49375
3.423150
2
158.90000
4.9497475
5
157.36000
1.9060430
10
160.37000
4.903298
13
159.55385
8.704751
ITEM_F001
여성
14
13
159.90000
7.355723
16
159.35000
4.665047
15
161.04000
4.529869
2
155.60000
7.7781746
4
158.32500
5.3080913
8
161.87500
4.987341
8
158.96250
6.857100
ITEM_F001
여성
15
18
162.31667
5.818353
13
162.40000
6.858450
22
160.62273
5.114678
2
159.95000
3.1819805
1
162.00000
NA
8
160.70000
3.706751
18
160.38333
3.873021
ITEM_F001
여성
16
14
159.31429
5.439154
24
160.92083
5.050095
21
159.68095
5.956309
2
158.65000
0.4949747
3
165.06667
0.8504901
7
159.14286
7.628424
19
161.43684
4.344883
ITEM_F001
여성
17
15
160.96000
4.036760
19
161.98421
3.481102
17
159.34706
6.197491
3
161.00000
1.5620499
6
158.73333
3.7494889
8
162.43750
4.955210
14
162.38571
5.063574
ITEM_F001
여성
18
6
161.15000
6.338060
7
160.47143
6.273945
5
163.08000
4.930213
2
164.50000
5.6568542
3
156.20000
3.5930488
11
162.87273
7.072777
12
160.39167
8.397668
ITEM_F002
남성
13
16
56.94375
15.884289
20
64.26500
15.545562
26
63.73077
16.570716
1
97.50000
NA
2
72.85000
36.4159992
3
60.93333
9.154416
11
64.41818
20.188453
ITEM_F002
남성
14
16
59.13125
11.659086
17
63.07647
14.848086
32
62.96875
13.394256
3
63.06667
8.2778822
2
91.00000
21.9203102
7
72.95714
26.349058
18
63.50556
21.315873
ITEM_F002
남성
15
16
104.26250
173.489050
22
66.11364
15.825425
24
68.09167
14.052446
3
72.56667
8.3930527
2
69.20000
0.1414214
15
74.46000
17.230695
17
63.67059
12.500138
ITEM_F002
남성
16
15
66.78667
9.549336
32
73.22187
13.522806
23
65.82174
9.863153
4
60.87500
4.6800107
7
76.31429
9.4735471
16
66.16875
9.440602
11
67.37273
9.252361
ITEM_F002
남성
17
11
77.20909
9.333215
26
67.40000
12.206883
30
71.20667
21.510125
5
71.56000
10.2600195
10
86.48000
25.3946101
11
70.89091
13.501293
17
72.18824
11.797186
ITEM_F002
남성
18
11
67.73636
14.405573
14
73.68571
16.877015
5
76.06000
22.125845
4
76.50000
8.8690473
6
80.53333
18.3988768
14
81.91429
14.448788
15
71.98000
15.796347
ITEM_F002
여성
13
17
52.73529
13.056413
11
51.02727
12.546481
16
49.35000
7.319381
2
53.00000
4.2426407
5
50.38000
6.3762842
10
59.63000
15.168831
13
55.63846
15.079596
ITEM_F002
여성
14
13
53.63846
16.585965
16
52.63750
5.889298
15
58.50000
14.159600
2
62.65000
2.0506097
4
58.05000
8.8925062
8
57.45000
11.006751
8
55.66250
15.383752