코드
load(here::here("data", "missing_data.RData"))
ls()[1] "df_full" "df_miss_1" "df_miss_2" "df_miss_3"이장에서는 결측자료의 발생원인과 유형에 대하여 살펴보고 싱제 자료를 이용한 결측값에 대한 처리를 연습해 본다.에 대한 전반적인 이해를 해보자.
데이터 분석에서 신뢰할 수 있는 결과를 도출하기 위해서는 정확하고 완전한 데이터를 확보하는 것이 필수적이다. 그러나 현실에서는 다양한 이유로 인해 데이터의 일부가 누락되는 결측값(missing data) 문제가 발생한다. 결측값은 데이터 수집, 입력, 저장, 관리 등의 다양한 과정에서 생길 수 있으며, 연구 설계 및 방법론의 한계로 인해 발생하기도 한다. 이러한 결측값은 단순한 누락된 정보 이상의 의미를 가지며, 분석의 신뢰성과 해석 가능성에 큰 영향을 미칠 수 있다.
결측값이 포함된 데이터는 표본의 대표성을 저하시킬 수 있으며, 분석 결과를 왜곡시킬 가능성이 크다. 또한, 결측값을 처리하는 방식에 따라 분석 결과가 달라질 수 있어 연구자가 신중하게 접근해야 한다. 특히, 통계적 검정과 추정의 정확도가 낮아지거나, 데이터 활용의 효율성이 감소하는 등의 문제가 발생할 수 있다. 따라서 결측값이 발생하는 원인을 파악하고, 이에 대한 적절한 처리 방법을 적용하는 것은 데이터 분석에서 필수적인 과정이다.
이 장에서는 결측값이 발생하는 주요 원인을 분석하고, 결측값이 통계 분석에 미치는 영향을 체계적으로 살펴본다. 이를 통해 데이터의 완전성을 유지하고 분석 결과의 신뢰성을 높이는 전략을 모색할 수 있을 것이다.
데이터 분석에서 결측값은 연구의 신뢰성을 저하시킬 수 있는 중요한 요소이다. 결측값이 발생하는 원인은 다양하며, 이는 데이터 수집, 입력 및 처리, 저장 및 관리, 연구 설계 등의 과정에서 나타날 수 있다. 또한, 결측값은 통계 분석의 정확성과 신뢰성에도 영향을 미칠 수 있어 이에 대한 적절한 이해와 처리가 필수적이다.
결측값은 데이터가 정상적으로 수집·입력·저장되지 못한 경우 발생하며, 그 원인은 다음과 같이 네 가지 주요 과정에서 찾을 수 있다.
데이터가 처음 수집되는 단계에서 결측값이 발생할 수 있다.
데이터가 입력되거나 변환되는 과정에서 실수나 오류로 인해 결측값이 발생할 수 있다.
데이터가 저장되고 관리되는 과정에서도 결측값이 발생할 가능성이 있다.
연구 설계 자체의 한계로 인해 데이터를 충분히 확보하지 못하는 경우도 있다.
결측값은 통계 분석의 신뢰성을 저하시킬 수 있으며, 분석 결과의 해석과 활용에 여러 가지 문제를 야기할 수 있다. 결측값이 미치는 주요 영향은 다음과 같다.
결측값은 데이터 분석 과정에서 피할 수 없는 문제이며, 이를 적절히 처리하지 않으면 연구의 신뢰성과 분석 결과의 정확성이 크게 저하될 수 있다. 따라서 데이터 수집, 입력, 저장, 관리 및 분석 과정에서 결측값을 최소화하기 위한 전략을 마련하는 것이 필요하다. 또한, 결측값이 발생했을 때 이를 올바르게 처리하는 방법을 적용하여 통계 분석의 신뢰성과 활용도를 높이는 것이 중요하다.
데이터 분석에서 결측값을 효과적으로 처리하기 위해서는 먼저 결측값의 분포와 패턴을 정확히 파악하는 과정이 필요하다. 단순히 결측값이 존재하는지 여부만 확인하는 것이 아니라, 결측값이 어떻게 분포되어 있으며 특정 변수 간에 어떤 관계를 형성하는지 분석하는 것이 중요하다. 이를 통해 결측값이 데이터에 미치는 영향을 평가하고, 적절한 보완 및 대체 방법을 결정할 수 있다.
데이터에 결측값이 포함되어 있을 경우, 이를 무작정 삭제하거나 단순한 대체 값으로 채우는 것은 적절하지 않을 수 있다. 왜냐하면 결측값의 발생 원인과 분포 형태에 따라 분석 결과에 미치는 영향이 다를 수 있기 때문이다. 따라서 결측값을 처리하기 전에 반드시 결측값의 분포와 구조를 면밀히 분석해야 한다.
결측값이 특정 변수에 집중적으로 발생하는지, 여러 변수에서 동시에 나타나는지, 결측값이 일정한 패턴을 가지고 있는지 등의 요소를 파악하는 것은 이후 분석의 정확성을 높이는 데 중요한 역할을 한다.
결측값의 구조를 이해하기 위해서는 여러 가지 분석 기법을 활용할 수 있다. 대표적인 방법은 다음과 같다.
먼저, 데이터의 각 변수에서 결측값이 얼마나 발생했는지를 파악해야 한다. 이를 위해 변수별로 결측값의 개수와 비율을 계산하는 것이 기본적인 방법이다. 특정 변수에서 결측값이 과도하게 많다면 해당 변수를 분석에 포함할 것인지, 대체 값을 사용할 것인지 등을 고려해야 한다.
데이터에 존재하는 여러 변수들 간의 결측값 분포를 확인하는 것도 중요하다. 특정 변수에서 결측값이 발생할 때 다른 변수에서도 동일한 패턴으로 결측값이 발생하는지 확인하는 과정이 필요하다. 이를 통해 결측값이 무작위(random missing)인지, 아니면 특정한 규칙을 가지고 있는지 판단할 수 있다.
일부 변수에서 발생한 결측값이 다른 변수의 결측값과 관련되어 있을 수 있다. 예를 들어, 특정 연령대에서 설문 응답이 누락되는 패턴이 있다면, 연령 변수와 설문 응답 변수 간의 연관성을 고려해야 한다. 이를 파악하기 위해 변수 간의 결측값 관계를 분석하는 것이 필요하다.
데이터 분석에서 결측값을 적절히 처리하는 것은 연구의 신뢰성을 보장하는 중요한 요소이다. 결측값을 방치하면 분석 결과의 왜곡을 초래할 수 있으며, 잘못된 결론으로 이어질 위험이 크다. 하지만 모든 결측값이 동일한 방식으로 처리될 수 있는 것은 아니다. 데이터의 특성과 결측값 발생 패턴에 따라 적절한 처리 방법을 신중히 선택해야 한다.
결측값을 처리하는 다양한 방법이 존재하지만, 특정한 상황에서 반드시 사용해야 하는 고정된 방법은 없다. 그렇기 때문에 연구자는 전반적인 결측값 처리 기법을 숙지한 후, 데이터의 특성과 분석 목적에 맞는 방법을 직접 선택하는 것이 바람직하다.
데이터 분석에서 결측값을 처리하는 다양한 방법이 존재하지만, 보다 근본적으로 중요한 것은 애초에 결측값이 발생하지 않도록 하는 것이다. 결측값이 발생한 후 이를 보완하는 작업은 필연적으로 분석의 신뢰성을 저하시킬 위험이 있으며, 데이터의 원래 정보를 온전히 복원하기 어렵다. 따라서 결측값을 줄이기 위한 사전 예방 조치가 무엇보다 중요하며, 이는 시간과 비용을 투자할 가치가 있는 과정이다.
많은 연구와 실무에서 결측값이 발생하면 이를 삭제하거나 평균값, 회귀 모델 등을 활용하여 대체하는 방식으로 해결하려 한다. 하지만 어떤 방법을 사용하든, 결측값을 대체한 데이터는 원본 데이터와 동일한 정보량을 갖지 못한다는 점을 간과해서는 안 된다. 결측값 대체 과정에서 데이터의 변동성이 줄어들거나, 특정 패턴이 왜곡될 수 있으며, 결과적으로 분석의 신뢰성과 예측력도 낮아질 가능성이 크다.
결측값을 최소화하는 것이 중요하다. 하지만 현실적으로 결측값이 발생하는 경우, 다양한 보완 방법을 활용하여 데이터를 최대한 보존하는 방향으로 처리해야 한다.
삭제법 (Deletion Method)
행 삭제 (Listwise Deletion): 결측값이 포함된 레코드(행)를 제거하는 방식
열 삭제 (Variable Deletion): 특정 변수(열)에서 결측값이 많을 경우, 해당 변수를 분석에서 제외하는 방식
이 방법은 데이터가 완전 무작위로 결측되는 경우(MCAR; Missing Completely At Random) 유용할 수 있다. 그러나 데이터 손실이 크며, 표본 크기가 급격히 줄어들 수 있다는 단점이 있다.
단순 대체법 (Simple Imputation)
예측 모델 기반 대체 (Model-Based Imputation)
다중 대체법 (Multiple Imputation, MI)
결측값 처리 방법은 데이터의 특성과 분석 목적에 따라 신중하게 선택해야 한다. 무조건적인 삭제는 데이터 손실을 초래할 수 있으며, 단순 대체법은 분석 결과를 왜곡할 가능성이 있다. 보다 정교한 예측 모델 기반 대체법이나 다중 대체법을 활용하면 데이터의 패턴을 보존하면서도 결측값 문제를 효과적으로 해결할 수 있다.
궁극적으로 중요한 것은 결측값이 분석 결과에 미치는 영향을 최소화하는 방향으로 처리 전략을 설정하는 것이다. 연구자는 다양한 방법을 이해하고, 데이터의 특성을 고려하여 최적의 접근법을 선택하는 것이 필요하다.
다양한 라이브러리를 활용하면 결측값의 위치와 패턴을 직관적으로 확인할 수 있으며, 이를 통해 결측값이 무작위로 발생한 것인지, 특정 그룹이나 변수에 집중적으로 나타나는지를 분석할 수 있다. 이러한 분석은 결측값 처리 방법을 결정하는 중요한 기초 자료가 되며, 분석 결과의 신뢰성을 높이는 데 기여한다.
결측값을 효과적으로 처리하기 위해서는 먼저 데이터 내에서 결측값이 어떻게 분포하고 있는지를 분석하는 과정이 필수적이다. 변수별 결측값의 빈도와 비율을 분석하고, 여러 변수 간 결측값의 위치와 패턴을 살펴봄으로써 결측값이 연구 결과에 미칠 영향을 최소화할 수 있다. 이를 위해 적절한 통계 프로그램과 시각화 기법을 활용하면 보다 정확한 결측값 분석이 가능하며, 이후의 데이터 처리 및 분석 과정에서 신뢰성을 확보할 수 있다.
결측값의 분포와 패턴을 보다 효과적으로 분석하기 위해서는 통계 프로그램 및 시각화 도구를 활용하는 것이 유용하다. 이를 통해 결측값이 무작위로 발생한 것인지, 특정 패턴을 가지고 있는지 확인할 수 있으며, 이후 결측값을 보완하는 전략을 수립하는 데 도움을 줄 수 있다.
R에서는 결측값의 분석에 유용한 다음과 같은 패키지들이 있다.
DescTools 패키지
PlotMiss 함수를 사용하여 결측값의 위치와 비율을 시각화할 수 있다.ggmice 패키지 +plot_pattern 함수를 사용하여 결측값의 패턴을 시각화할 수 있다.
mice 패키지
mice 함수를 사용하여 결측값을 대체한 자료를 생성naniar 패키지
Python에서는 pandas 라이브러리를 이용하여 결측값의 빈도와 비율을 쉽게 확인할 수 있으며, missingno 라이브러리를 활용하면 결측값의 분포를 시각적으로 분석할 수 있다.
서울 열린 데이터 광장에서 제공하는 2019년 서울특별시 부동산 실거래가 정보를 가진 자료를 어번 예제에 사용하려고 한다. 2019년 거래하여 신고한 주택들의 위치와 정보 그리고 실거래 가격이 포함된 총 67238건의 실제 거래자료는 거래된 주택에 대한 실거래가 등 다양한 정보를 포함하고 있다.
본 예제에서는 실습을 위하여 원래 자료의 일부를 분석할 것이며 교육을 위하여 결측값의 유형이 서로 다른 합성 자료(synthetic data)도 사용할 것이다. 다음은 이 절에서 사용할 예제 자료의 특성은 다음과 같다.
예제 자료에서는 이미 지어진 아파트의 거래만 선택(분양 아파트 제외)
아파트의 거래에서 1000건의 자료만 임의로 선택
거래가격의 단위는 백만원으로 변경
결측값이 없는 원자료와 결측값의 유형이 다른 3개의 합성 자료로 구성
예제에서 사용할 자료는 다음과 같은 6개의 컬럼을 가지고 있다.
이제 예제 자료를 포함한 R 데이터를 불러오자.
load(here::here("data", "missing_data.RData"))
ls()[1] "df_full" "df_miss_1" "df_miss_2" "df_miss_3"결측값이 없는 예제 자료 df_full 의 일부는 아래와 같다. 결측값이 존재하는 다른 3개의 자료(df_miss_1, df_miss_2, df_miss_3)는 결측값이 없는 예제 자료 df_full 에서 결측값이 특정한 패턴을 가지고 발생하도록 만든 합성자료이다.
knitr::kable(df_full %>% head(10))| 실거래가아이디 | 자치구명 | 건축년도 | 건물면적 | 층정보 | 물건금액 |
|---|---|---|---|---|---|
| 1 | 송파구 | 2007 | 59.88 | 12 | 1330 |
| 2 | 용산구 | 2004 | 126.19 | 21 | 1560 |
| 3 | 성동구 | 2000 | 59.96 | 12 | 750 |
| 4 | 서대문구 | 2004 | 84.88 | 5 | 400 |
| 5 | 성동구 | 2016 | 84.64 | 6 | 1300 |
| 6 | 중랑구 | 1997 | 84.08 | 16 | 450 |
| 7 | 광진구 | 2001 | 84.91 | 12 | 1025 |
| 8 | 송파구 | 2006 | 135.82 | 30 | 2332 |
| 9 | 성북구 | 2008 | 84.83 | 4 | 620 |
| 10 | 성북구 | 1994 | 84.90 | 9 | 505 |
결측값이 있는 자료 df_miss_1 의 일부는 다음과 같으며 결측값은 NA 로 표시된다.
knitr::kable(df_miss_1 %>% head(10))| 실거래가아이디 | 자치구명 | 건축년도 | 건물면적 | 층정보 | 물건금액 |
|---|---|---|---|---|---|
| 1 | 송파구 | 2007 | 59.88 | NA | NA |
| 2 | 용산구 | 2004 | 126.19 | 21 | 1560 |
| 3 | 성동구 | 2000 | NA | 12 | 750 |
| 4 | 서대문구 | 2004 | 84.88 | 5 | 400 |
| 5 | 성동구 | 2016 | 84.64 | 6 | 1300 |
| 6 | 중랑구 | 1997 | 84.08 | 16 | 450 |
| 7 | 광진구 | 2001 | NA | 12 | 1025 |
| 8 | 송파구 | NA | 135.82 | 30 | 2332 |
| 9 | 성북구 | 2008 | 84.83 | 4 | 620 |
| 10 | 성북구 | 1994 | 84.90 | 9 | 505 |
먼저 결측값이 있는 자료 df_miss_1 에서 결측값의 위치를 시각적으로 살펴보기 위하여 다음과 같이 PlotMiss 함수를 사용해 보자.
PlotMiss(df_miss_1, main="결측값의 위치와 비율")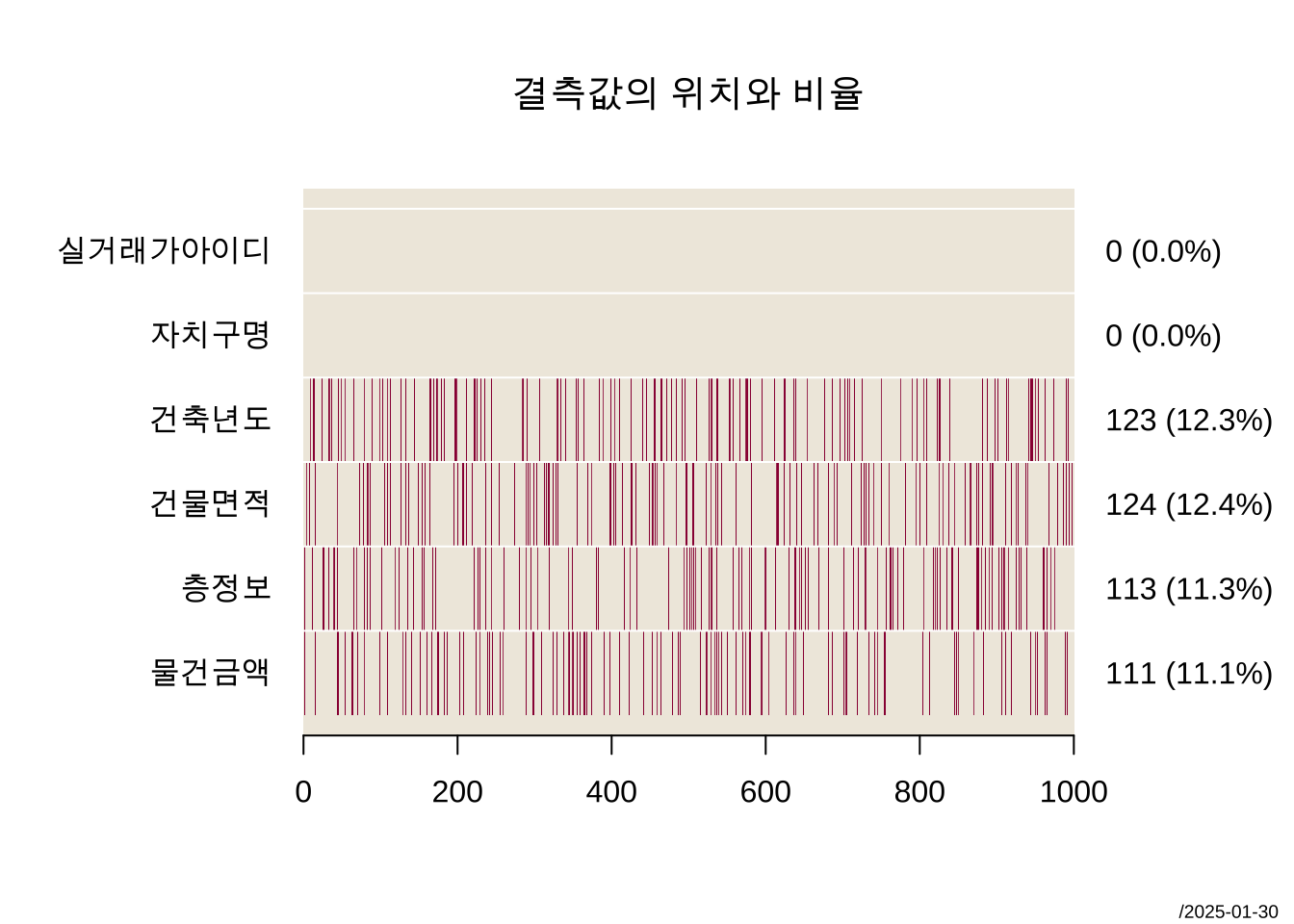
그림 2.1 을 보면 4개의 변수에 결측값이 존재하는 자료이며 그림 오른쪽에 각 변수에 존재하는 결측값의 개수외 비율이 나타난다.
이제 plot_pattern 함수를 이용하여 결측가 발생하는 패턴에 대해서 살펴보자
plot_pattern(df_miss_1, square= FALSE) 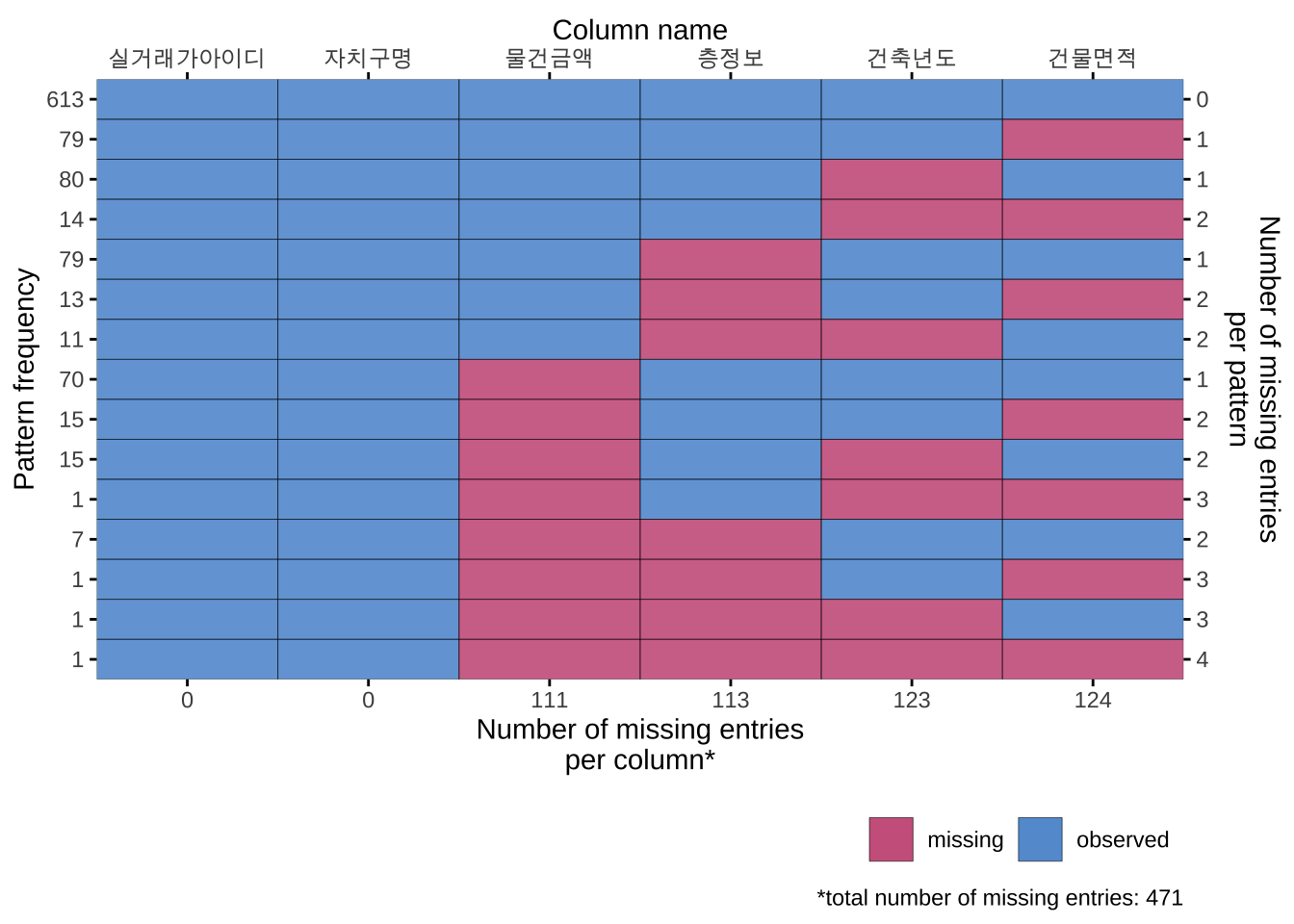
그림 2.2 의 각 행은 결측값이 나타난 유형을 알려주며, 오른쪽의 숫자는 주어진 패턴으로 나타난 결측된 컬럼의 개수이다. 왼쪽은 결측값이 나타난 유형에 속하는 자료의 개수(pattern frequency)이다. 아래 쪽에 나타난 숫자는 각 컬럼에 나타나는 결측값의 개수이다.
그림 2.2 에 나타나 결측값의 발생 형태를 보면 특별한 경향이 없이 4개의 변수에서 무작위로 발생한 것으로 판단된다.
다음으로 결측값이 있는 자료 df_miss_2 에서 결측값의 위치를 시각적으로 살펴보자.
PlotMiss(df_miss_2, main="결측값의 위치와 비율")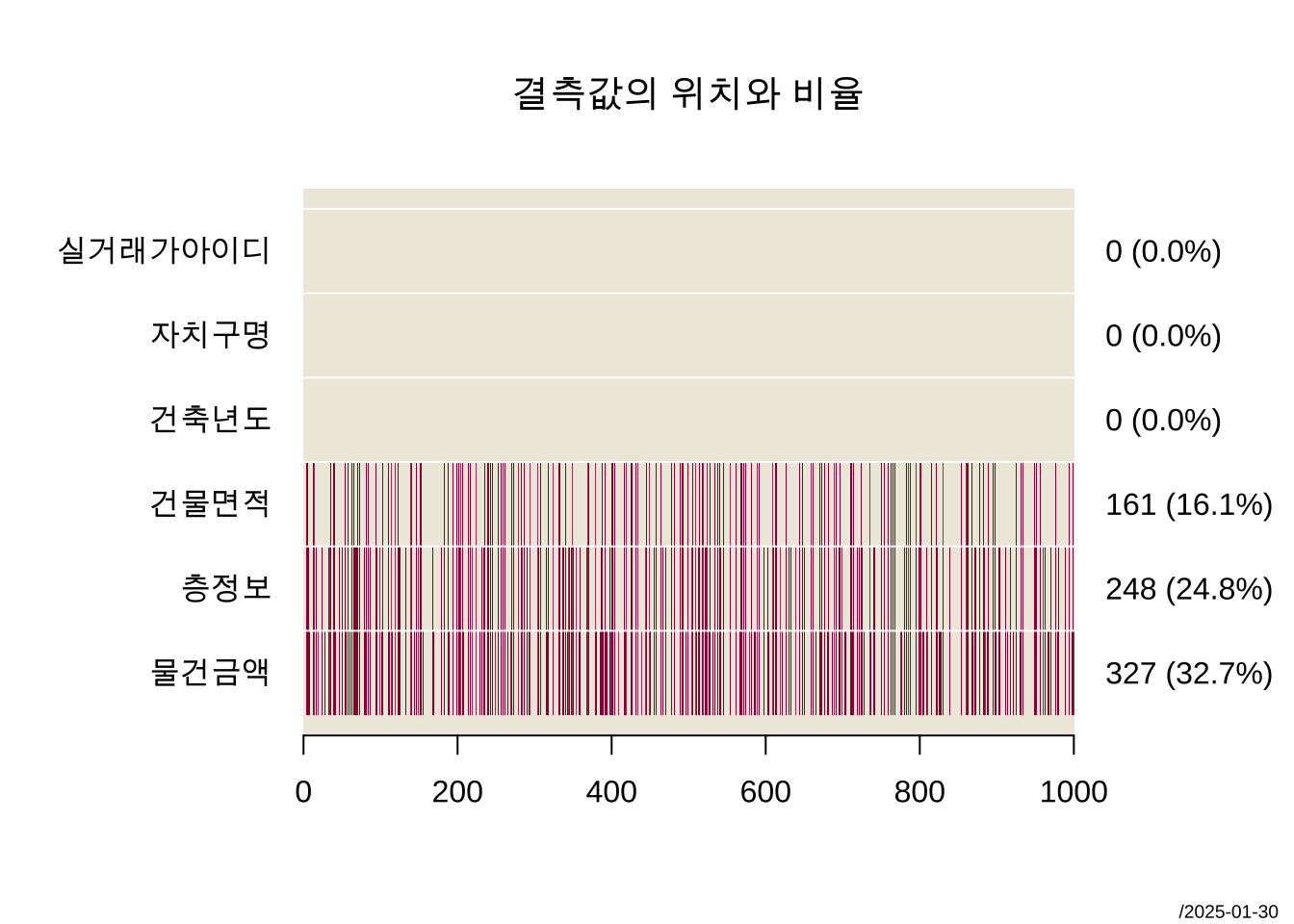
plot_pattern 함수를 이용하여 결측가 발생하는 패턴에 대해서 살펴보자
plot_pattern(df_miss_2, square= FALSE) 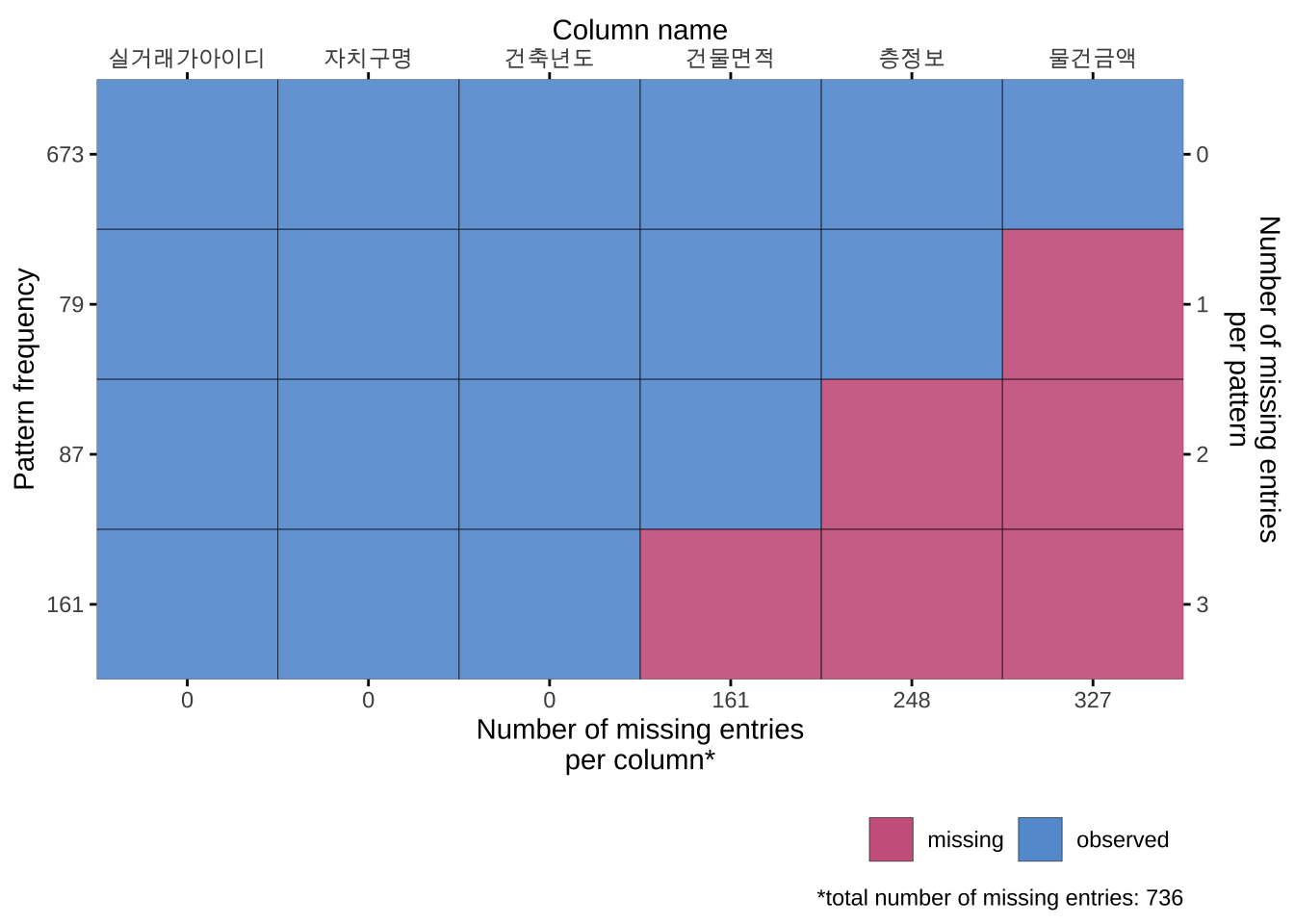
그림 2.4 에 나타나 결측값의 발생 형태를 보면 특별한 경향이 있는 것으로 보인다.
df_miss_2 자료에서는 세 개의 변수에서 결측값이 존재하며, 이 결측값들은 단순한 무작위적 발생이 아닌 계층적인 패턴을 따르는 것으로 나타났다. 층정보컬럼는건물면적` 값이 결측된 경우, 반드시 결측되는 구조를 보였다. 즉, 건물면적에 대한 정보가 없는 경우 층수 역시 제공되지 않는 패턴이 관찰된 것이다. 이러한 상관관계는 데이터의 누락이 단순한 실수나 오류에서 비롯된 것이 아니라, 특정 컬럼 간 논리적인 관계 속에서 발생하고 있음을 보여준다.
또한, 물건금액 컬럼의 경우, 층정보가 결측되면 자동으로 결측값이 되는 구조를 보였다. 이는 물건금액이 층정보에 의존적이라는 점을 시사하며, 데이터의 구조적 특성을 이해하는 데 중요한 단서가 된다.
다음은 naniar 패키지에서 제공하는 결측값의 위치를 제공하는 함수 geom_miss_point() 를 사용하여 건축년도 와 건물면적 의 관게를 나타내는 산점도(scatter plot)에 건물면적이 없는 결측값을 나타낸 그림이다.
ggplot(df_miss_2,
aes(x = `건축년도`,
y = `건물면적`)) +
geom_miss_point()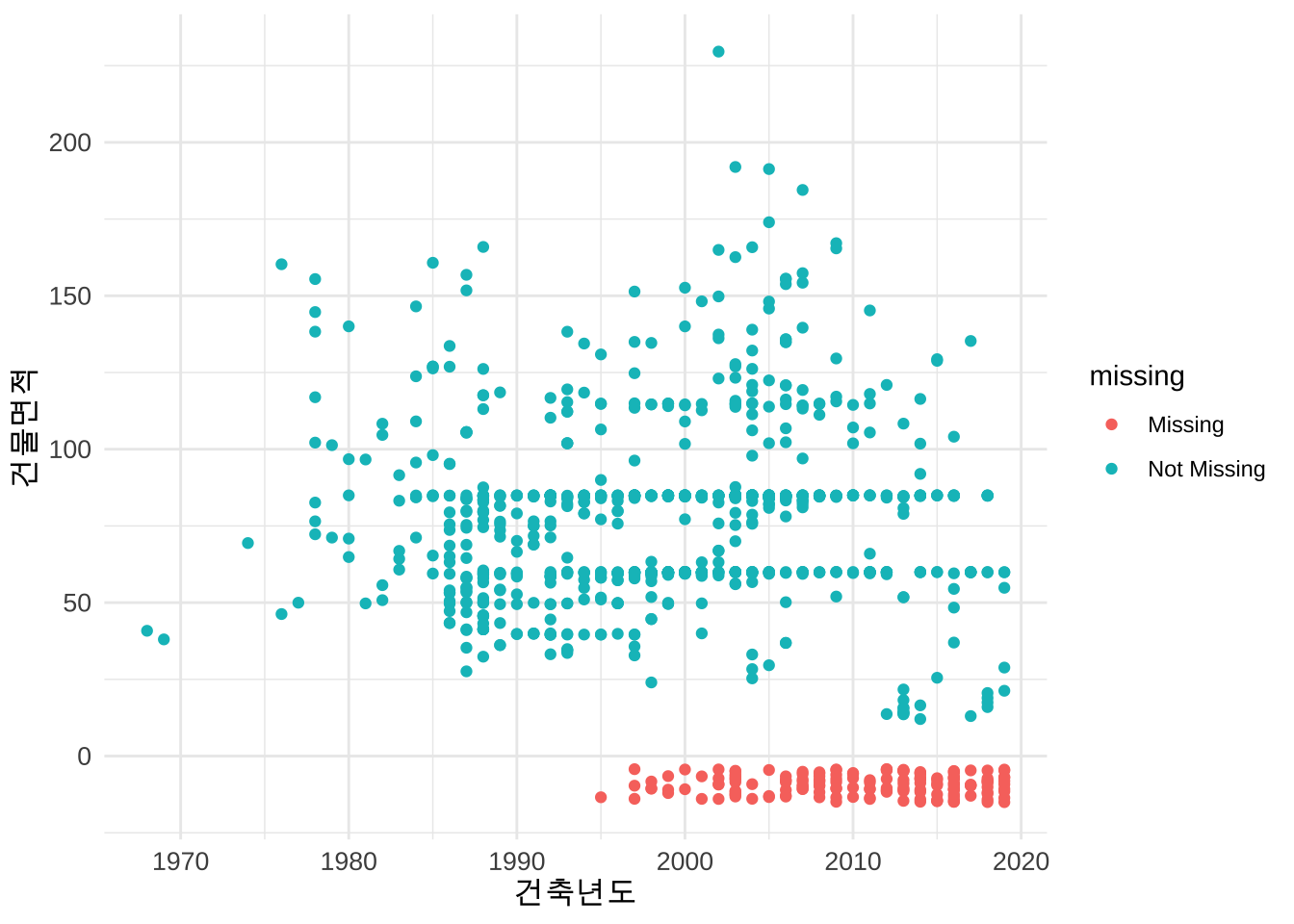
건물면적 컬럼의 경우, 건축연도가 최근일수록 결측값이 발생할 가능성이 높은 것으로 확인된다. 이는 건축연도가 최신일수록 특정 정보가 기록되지 않는 경향이 있음을 시사한다.
마지막으로 결측값이 있는 자료 df_miss_3 에서 결측값의 위치를 시각적으로 살펴보자.
PlotMiss(df_miss_2, main="결측값의 위치와 비율")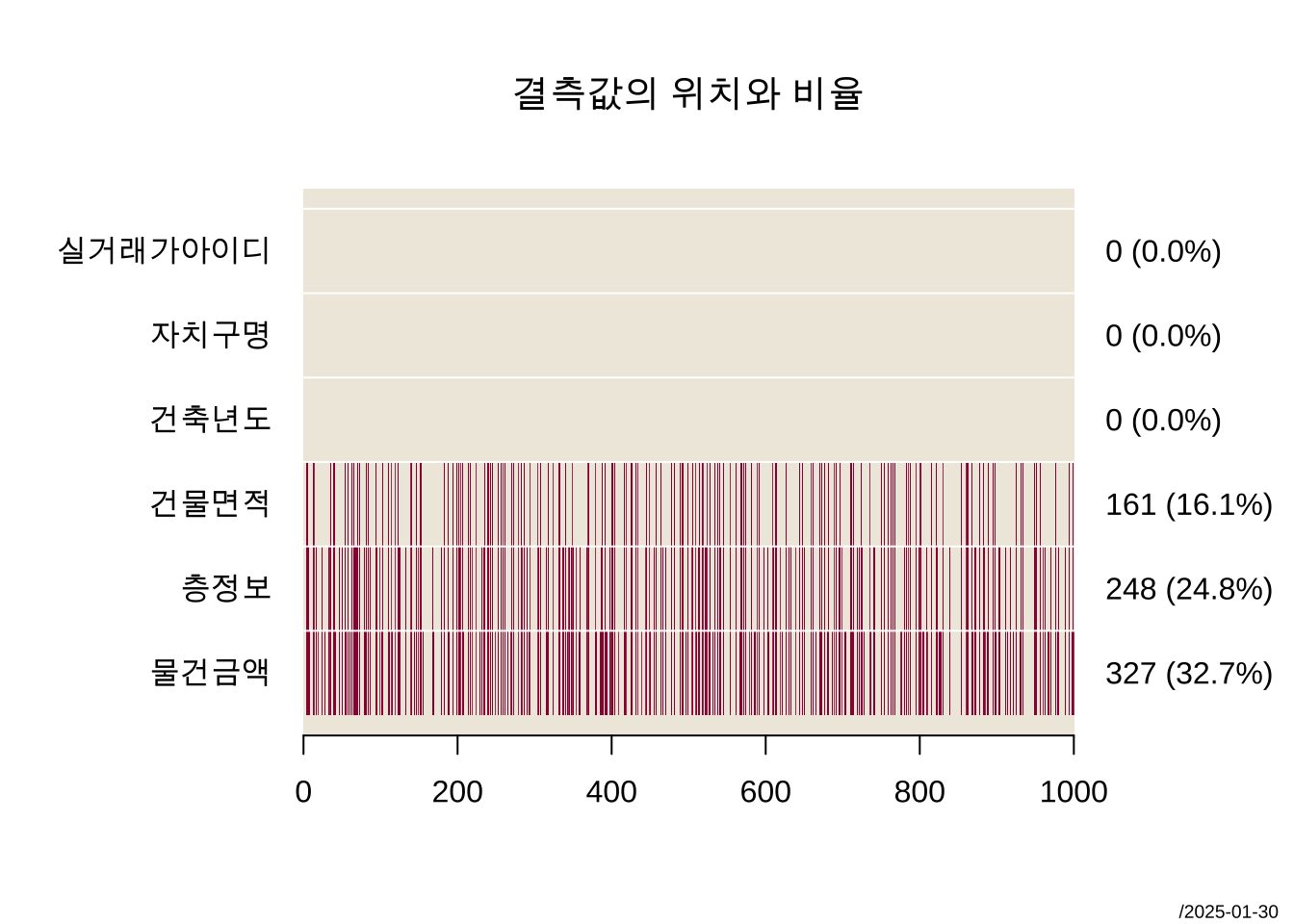
plot_pattern 함수를 이용하여 자료 df_miss_3 에서 결측가 발생하는 패턴에 대해서 살펴보자
plot_pattern(df_miss_3, square= FALSE) 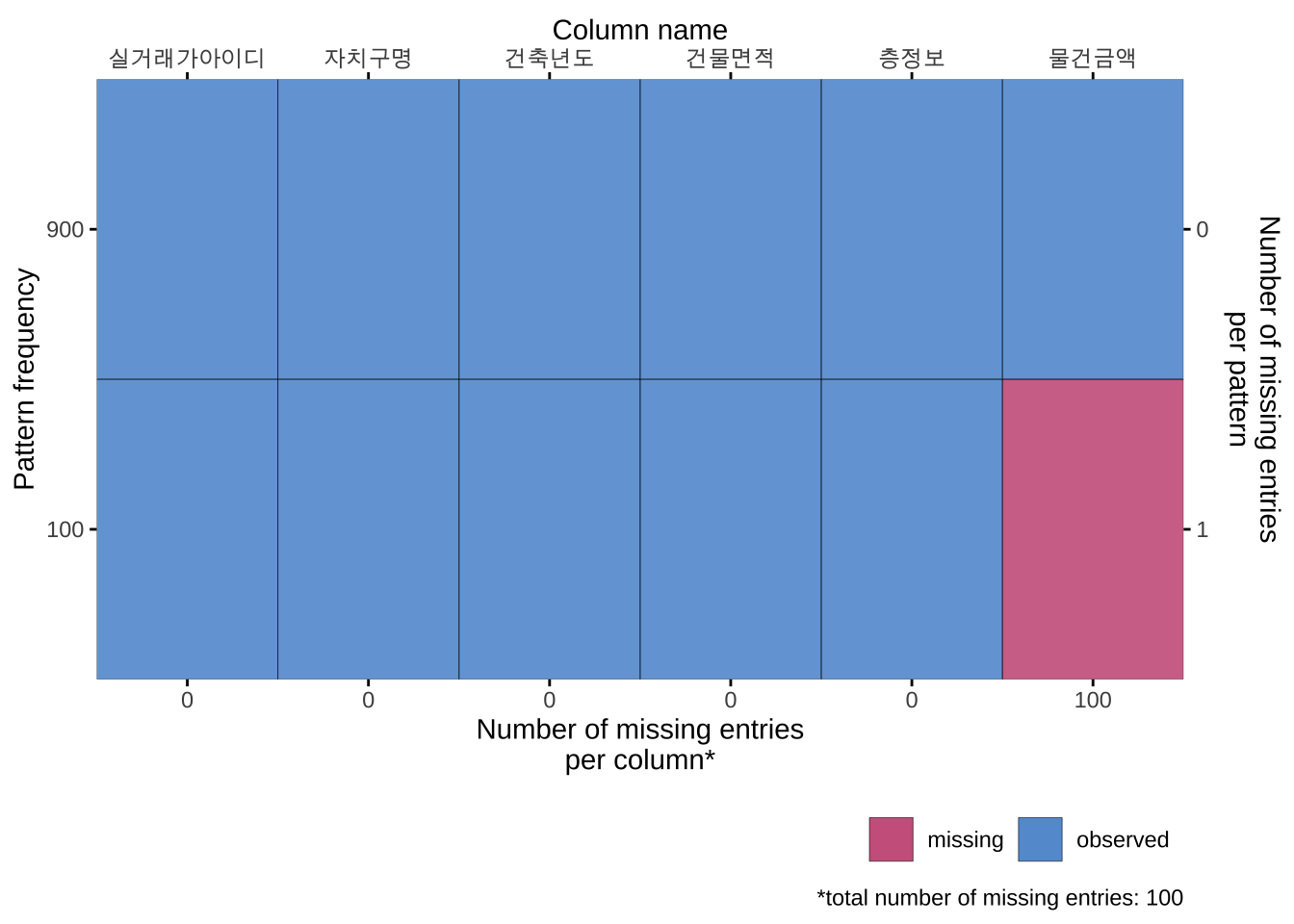
그림 2.7 에 나타나 결측값의 발생 형태를 보면 자료레서 가장 관심있는 컬럼인 물건금액 에서만 10% 결측이 발생하였다. 물건금액 이 중요한 변수이기 떄문에 결측값이 발생하는 패컨이 무작위인지 아니면 특별한 패턴을 가지고 있는지가 중요하다.
이제 건물면적 에 따라서 변하는 물건금액 에 대한 관계를 나타내는 산점도(scatter plot)에 건물면적이 없는 결측값을 나타낸 그림이다.
ggplot(df_miss_3,
aes(x = `건물면적`,
y = `물건금액`)) +
geom_miss_point()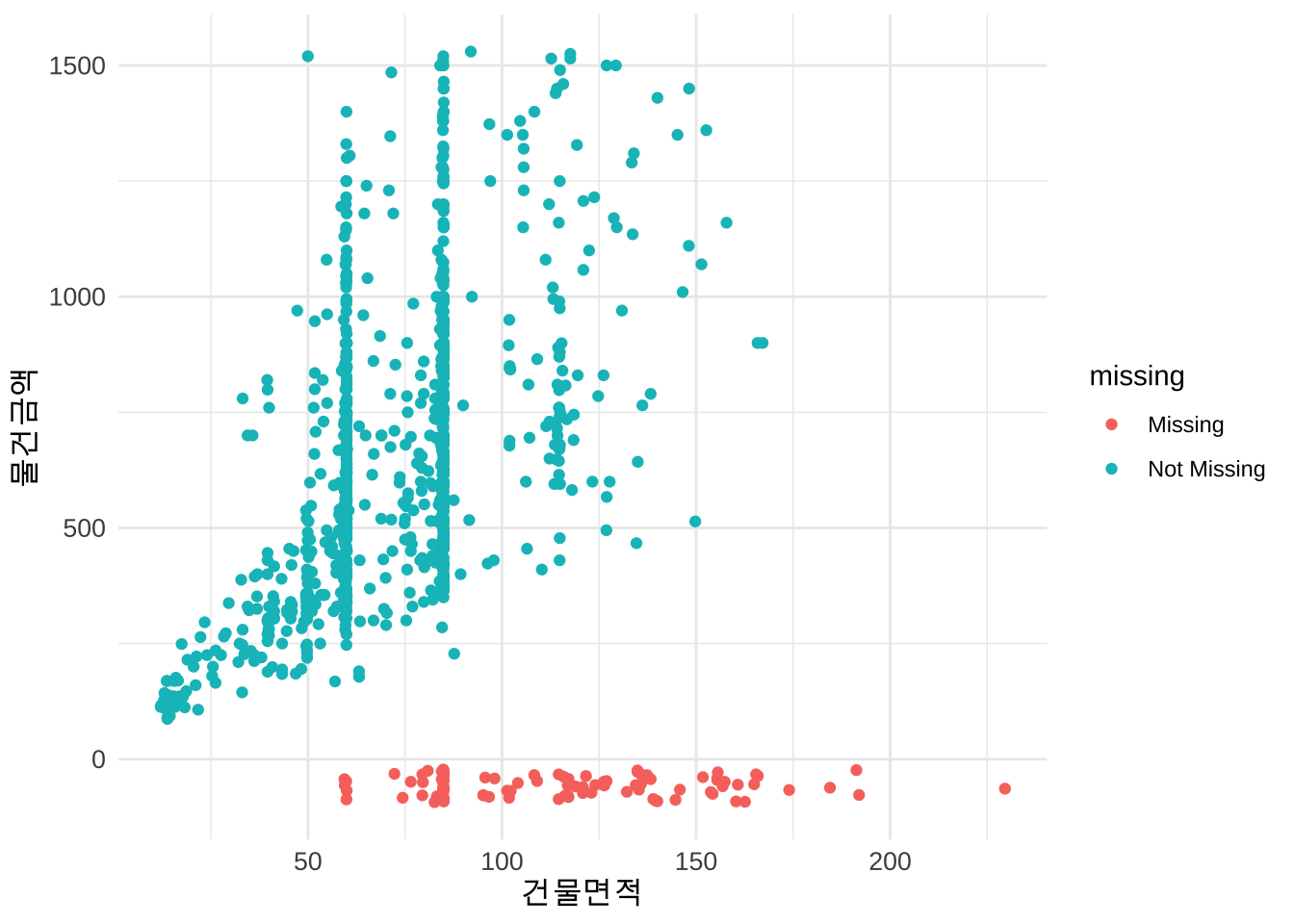
그림 2.8 를 보면 자료에 건물면적이 커질수록 물건금액 이 결측값이 나타날 경향이 큰 것으로 보인다. 특히, 건물면적이 매우 큰 자료에서는 물건금액 이 결측인 경우가 매우 많다. 이렇게 가장 관심있는 변수에서 나타나는 결측값의 패턴이 무작위가 아니라 자신의 값에 영향을 받는 경우, 결측값을 가진 단위를 제거한 자료를 분석한 결과는 실제 결과와 매우 다를 수 있다.
결측값의 발생 패턴을 무시한 채 단순히 보정하거나 제거할 경우, 데이터의 본질적인 특성을 왜곡할 위험이 있다. 따라서 결측값을 처리하기 전, 그 발생 구조를 면밀히 분석하고 적절한 보완 전략을 수립하는 것이 무엇보다 중요하다.
데이터 분석에서 결측값은 단순한 누락 이상의 의미를 지닌다. 특히, 결측값이 일정한 패턴을 보이며 발생할 경우, 이를 무작정 보완하거나 제거하는 것이 아니라 그 구조를 이해하는 것이 중요하다.